先日、Amazon Product (以下略) に、署名を組み込むことができたので、これも先日動作確認がとれた、Google App Engine for Pythonに組み込んでみる。
Python をやりだして間がないので、非常識な実装をしているかも・・・ が、まぁ気にせずに。
先日署名を組み込み、Amazon Web Services へリクエストするREST URLの生成、ブラウザでの動作確認ができたので、後やるべきことは、
- REST URL をリクエストして、レスポンスを取得する
- 取得したレスポンス(XML)を解析する
- 解析した内容からHTMLを作成する
- Google App Engine に組み込む
- 完成!
てな感じ。
以下詳細を記述
1.REST URL をリクエストして、レスポンスを取得
urllib2を利用する
import urllib2
:
f = urllib2.urlopen(url)
f.read() |
これだけ。んー楽だ。Pythonの人がJavaをまどろっこしがるのもわかる。
2.取得したレスポンス(XML)を解析する
XPathなども標準で使えるようだけど、まずは、単純な例なので、SAXパーサーを利用する。 この例を見ればやるべきことは一目瞭然。
ただ、解析しながら結果を生成していくのに、ハンドラ関数の外側で状態を管理しておきたいのだけれど、Pythonの変数とスコープの取り扱い方の常識が今ひとつわかっていない。グローバル(ファイル?)レベルでとりあつかっていいものなのかしら?サブクラス化したパーサーのインスタンスを作れるといいのだけれど。
インスタンスのメソッドとしてハンドラを持たせて、状態をインスタンスで管理することが可能。メソッドの第1引数には self を設定する必要があるので、シグネチャが変わるので無理だと思い込んでた。
|
>>> class Foo:
… f1 = ”
… def bar(self, msg):
… print msg
… self.f1 = ‘called’
… def status(self):
… print self.f1
…
>>> f = Foo()
>>> x = f.bar
>>> x(‘test’)
test
>>> f.status()
called
|
|
import urllib2
import xml.parsers.expat
# 要素の開始を処理するごとに呼び出されるハンドラ関数の定義
def StartElementHandler(name, attributes):
:
# 要素の終端を処理するごとに呼び出されるハンドラ関数の定義
def EndElementHandler(name):
:
# 文字データを処理するときに呼びだされるハンドラ関数の定義
def CharacterDataHandler(data):
:
# XMLParserの生成
p = xml.parsers.expat.ParserCreate()
# 生成したParserにハンドラをセット
p.StartElementHandler = StartElementHandler
p.EndElementHandler = EndElementHandler
p.CharacterDataHandler = CharacterDataHandler
# リクエストの実行
f = urllib2.urlopen(url)
# 解析
p.Parse(f.read())
|
上記、2で、XMLを解析しながら結果オブジェクトを作っておいて、それからHTMLを生成
4.Google App Engine に組み込む
上記手順を踏まえて、このあたりの雛形に、Amazon Web Servicesの呼び出しを組み込む。
import している、amazon_ecs は、前回作成したもの。 ItemSearch だけ実行できる状態。
localhostで、実行確認できたら、デプロイする。
5.完成!
|
#!Python2.6
# -*- coding: utf-8 -*-
from google.appengine.ext import webapp
from google.appengine.ext.webapp.util import run_wsgi_app
import amazon_ecs
import urllib2
import xml.parsers.expat
class SearchedItem:
”’ Amazon ItemSearch Operation の結果格納 ”’
def __init(self)__:
self.asin = ”
self.detailPageURL = ”
self.smallImageURL = ”
class SAXTagHandler:
def __init__(self):
# XMLParser(SAX)の状態制御
self.proc_start = False
self.img_start = False
self.now_key = ”
self.item_list = []
def startElementHandler(self, name, attributes):
”’ xml.parsers.expat XMLParser のハンドラ
要素の開始を処理するごとに呼び出される
@see http://www.python.jp/doc/release/lib/xmlparser-objects.html
”’
if name == ‘Items’:
self.proc_start = True
if name == ‘SmallImage’:
self.img_start = True
if self.proc_start:
if name == ‘Item’:
self.item_list.append(SearchedItem())
else:
self.now_key = name
def endElementHandler(self, name):
”’ xml.parsers.expat XMLParser のハンドラ
要素の終端を処理するごとに呼び出される
@see http://www.python.jp/doc/release/lib/xmlparser-objects.html
”’
if name == ‘Items’:
self.proc_start = False
if name == ‘SmallImage’:
self.img_start = False
def characterDataHandler(self, data):
”’ xml.parsers.expat XMLParser のハンドラ
文字データを処理するときに呼びだされる
@see http://www.python.jp/doc/release/lib/xmlparser-objects.html
”’
if self.proc_start:
idx = len(self.item_list)
idx = idx -1
if idx >= 0:
if self.now_key == ‘ASIN’:
self.item_list[idx].asin = data
if self.now_key == ‘DetailPageURL’:
self.item_list[idx].detailPageURL = data
if self.img_start and self.now_key == ‘URL’:
self.item_list[idx].smallImageURL = data
class MainPage(webapp.RequestHandler):
def get(self):
self.redirect(‘/am_is?q=amazon’)
class AmazonItemSearch(webapp.RequestHandler):
”’ Amazon Product Advertising API を利用し、キーワード検索を行う
example http://typea-mixi01.appspot.com/am_is?q=book
”’
def get(self):
#パラメータの切り出し request.getが機能しない
#keyword = self.request.get(‘q’)
keyword = ”
queries = self.request.query_string.split(‘&’)
for query in queries:
pair = query.split(‘=’)
if pair[0] == ‘q’:
keyword = pair[1]
break;
#パラメータのデコード
#@see http://www.findxfine.com/default/495.html
#FireFox のアドレスバーに漢字を打つとUTF-8でないコードにエンコードされてしまう?
keyword = urllib2.unquote(keyword) #.encode(‘utf-8’)
if keyword == ”:
keyword = ‘amazon’
operation = amazon_ecs.ItemSearch()
operation.keywords(keyword)
operation.search_index(‘Books’)
operation.response_group(‘Small’)
request = operation.request()
# XMLParserの生成とハンドラのセット
h = SAXTagHandler()
p = xml.parsers.expat.ParserCreate()
p.StartElementHandler = h.startElementHandler
p.EndElementHandler = h.endElementHandler
p.CharacterDataHandler = h.characterDataHandler
# リクエストの実行と解析
f = urllib2.urlopen(request)
p.Parse(f.read())
for itm in h.item_list:
self.response.out.write(‘<a href="%s" style="padding-left:2px" target="_blank"><img src="%s" border="0"/></a>’
% (itm.detailPageURL, itm.smallImageURL))
application = webapp.WSGIApplication([
(‘/’, MainPage),
(‘/am_is’, AmazonItemSearch)
], debug=True)
def main():
run_wsgi_app(application)
if __name__ == "__main__":
main()
|
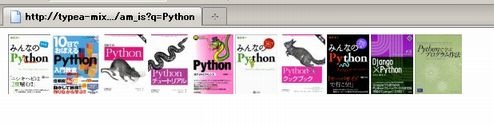
完成しました ただ、本のサムネイルを横に並べるだけですが。
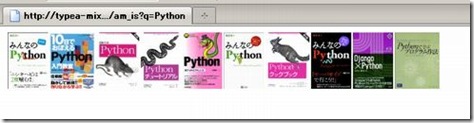
また一歩野望に近づいた!